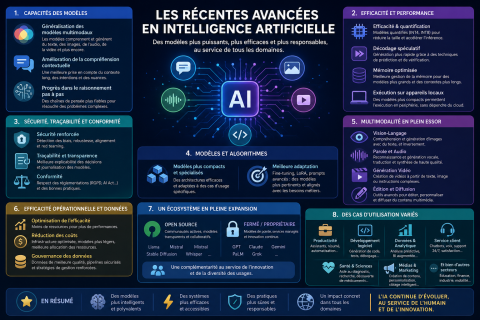
Les dernières évolutions en IA
En bref
- Généralisation des modèles multimodaux (texte, image, audio, vidéo) et amélioration nette de la compréhension contextuelle longue.
- Progrès du raisonnement pas à pas, de l’usage d’outils et du calcul adaptatif au moment de l’inférence.
- Accélérations majeures côté efficacité: quantification, décodage spéculatif, mémoire optimisée et exécution sur appareils locaux.
- Montée en puissance des approches open source et des petits modèles spécialisés finement ajustés.
- Renforcement des pratiques de sécurité, de traçabilité et de conformité (provenance, filtres, évaluation).
Modèles et algorithmes
- Modèles de fondation plus compacts ou experts: architectures denses et Mixture-of-Experts, spécialisation par domaine, et meilleures fenêtres de contexte (jusqu’aux millions de tokens en recherche).
- Raisonnement avancé: chaînes de raisonnement, arbres/graphes de pensée, supervision de processus, modèles orientés résolution de problèmes et augmentation du calcul à l’inférence.
- Préférences et alignement: RLHF, RLAIF, DPO/ORPO/KTO, modèles de récompense de processus et distillation du raisonnement.
- RAG évolutif (“RAG 2.0”): récupération structurée, agents orchestrant plusieurs outils, graphes de connaissances, contraintes de sortie et vérification factuelle.
Multimodalité
- Vision-langage: description, interrogation d’images, extraction de documents, UI grounding et compréhension de graphiques.
- Parole et audio: transcription robuste, traduction directe, synthèse et dialogues voix-à-voix temps réel.
- Génération vidéo et édition: diffusion/flow matching, cohérence temporelle accrue, conditionnement par texte, image ou audio.
- 3D et monde réel: NeRF/Gaussian Splatting, génération et reconstruction 3D guidées par le texte, simulation et robotique assistée par modèles.
Efficacité, coûts et matériel
- Optimisation mémoire et calcul: Flash/quantized attention, paged/KV-caching, planification du calcul et décodage spéculatif.
- Adaptation légère: LoRA/QLoRA, fine-tuning efficace sur données restreintes, entraînement avec données synthétiques de haute qualité.
- On-device et edge: exécution sur GPU/TPU/NPU embarqués, quantification 4–8 bits, confidentialité renforcée et latence réduite.
- Inférence haute performance: graph compilation, kernels spécialisés et bibliothèques optimisées pour le déploiement à grande échelle.
Qualité, sécurité et gouvernance
- Réduction des hallucinations: récupération de connaissances, contraintes de décodage, vérification par outils et auto-consistance.
- Sécurité et garde-fous: filtrage contextuel, red teaming, évaluation multi-axes (utilité, toxicité, partialité, robustesse).
- Provenance et intégrité: watermarking et normes de traçabilité des contenus, métadonnées C2PA et détection de deepfakes.
- Gouvernance des données: curation, déduplication, conformité aux droits d’auteur et documentation des sources.
Écosystème open source et fermé
- Modèles ouverts de 7–70B paramètres approchant des performances de très grands modèles sur des tâches ciblées.
- MoE ouverts offrant un bon compromis coût/qualité, avec routage efficace et latence maîtrisée.
- Montée de piles complètes open source: entraînement, évaluation, inférence distribuée et observabilité.
Cas d’usage en expansion
- Productivité: copilotes pour bureautique, gestion de connaissances, génération de rapports et assistance multilingue.
- Développement logiciel: complétion, refactorisation, génération de tests, agents couvrant tickets et CI/CD.
- Données et analytique: traduction NL→SQL, création de tableaux de bord, gouvernance et qualité des données assistées.
- Service client et opérations: routage, réponses contextualisées, automatisation de workflows avec vérification humaine.
- Santé et sciences: résumé clinique, extraction d’entités, hypothèses de recherche assistées et simulation.
- Médias et marketing: génération contrôlée de contenu, personnalisation et vérification de la cohérence de marque.
Bonnes pratiques de mise en production
- Évaluation continue: jeux de tests représentatifs, métriques holistiques et A/B testing en ligne.
- Observabilité: traçage, enregistrement des prompts, détection d’anomalies et boucles de feedback.
- Conception responsable: permissions d’outils minimales, PII redaction, politique de rétention et revue humaine pour actions à risque.
- Optimisation coût-performance: caching, batching, choix du modèle adapté par tâche et routage dynamique.
Tendances proches
- Raisonnement plus fiable et explicite avec vérification outillée.
- Multimodalité native et interactions temps réel.
- Généralisation de l’exécution locale et hybride cloud/appareil.
- Combinaisons neurales-symboliques et sorties structurées robustes.
- Se connecter ou s'inscrire pour publier un commentaire